Jobs¶
Jobs allow you to easily run your data processing and other computing tasks. You can schedule jobs or run them as one-offs. You choose a script you want to run and your desired execution environment, and Faculty will run it for you.
Contents
Glossary¶
A job defines the specification of a task to be run, principally containing a script to be run, its execution environment and a definition of parameters accepted by that job.
A parameter is a user-defined input that a job accepts. They can be assigned to a job in its definition and can be marked as mandatory or configured to only accept values of a specific format.
A run is an execution of a job, and is passed values for parameters in the job definition.
A run array contains multiple sub runs. It allows running the same job many times with different inputs, each executed on a separate server, but with grouped outputs.
Define a job¶
On the jobs screen, click the + button in the upper left corner of the screen to create a new job. After entering a suitable job name and description, you’ll be presented with the configuration screen for the job:
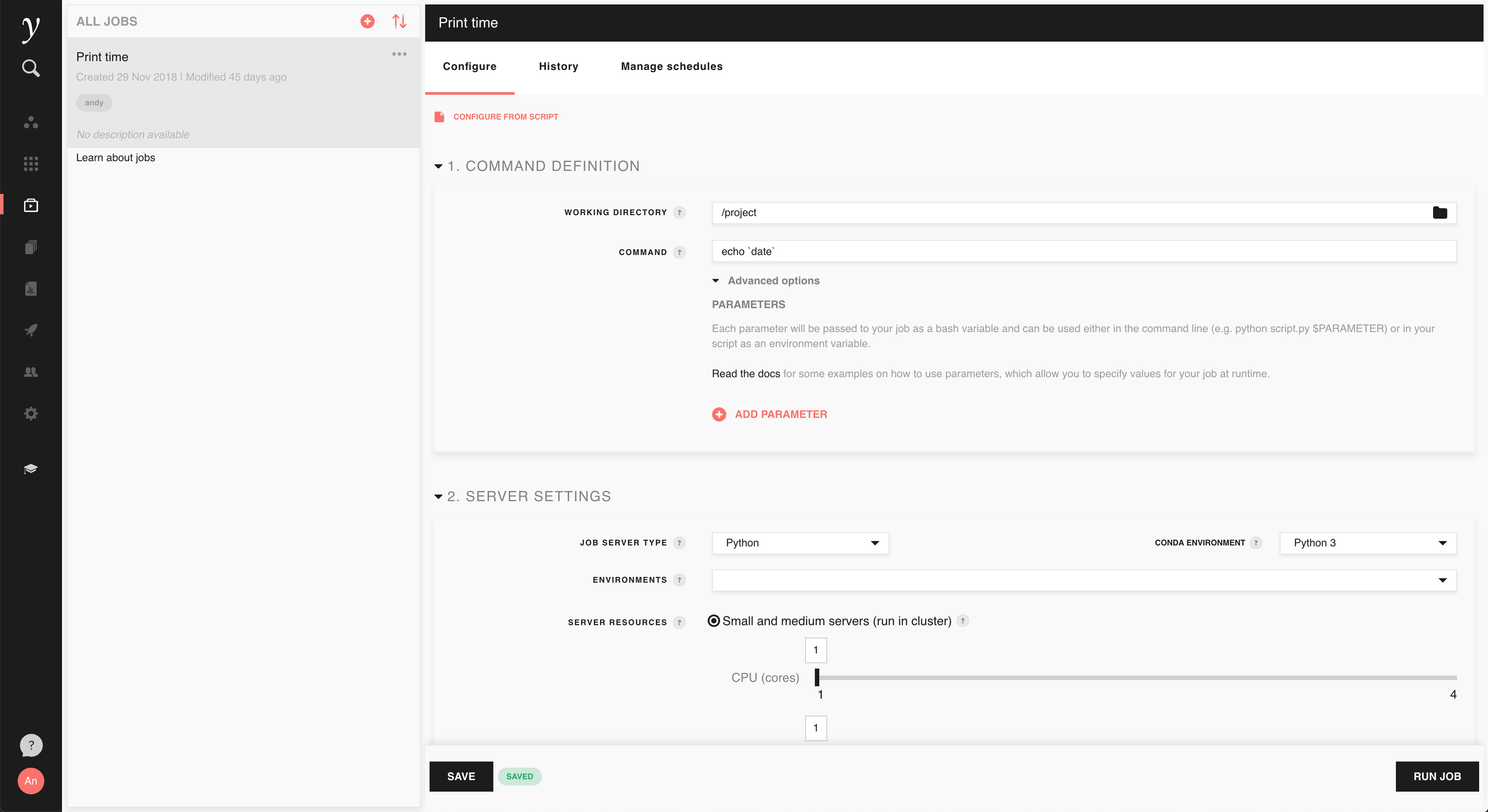
1. Command definition¶
First, you’ll want to set the working directory and command to be run. For example, if you have a Python script called ‘example.py’ in the ‘scripts’ directory of the project workspace, you can choose the ‘scripts’ directory as the working directory and ‘python example.py’ as the command.
Tip
If you’re not familiar with working directories, think of it as the place
where the command is run. If you open a terminal in Faculty and run
cd to change to the directory you’ve set as the working directory
and then run your command in the terminal, it’ll have the same effect as
setting the working directory in jobs.
Parameters¶
In the command definition section, you can optionally configure some parameters for your job. It’s not necessary to use parameters with jobs, but if your job takes some input that you wish to change each time you run it, parameters provide a convenient way to do this. For example, if you want to run a job 10 times, each with a different input file, you can use a parameter to do that.
In this example, consider that you have a script which reads and processes a file specified as a command line argument:
# example.py
import sys
from my_module import process_file
input_path = sys.argv[1]
process_file(input_path)
The above script can be run in the terminal with /project/data/input.txt as
the input with:
python example.py /project/data/input.txt
To configure your job to collect the input file as a parameter, first add a
parameter using the ‘Add parameter’ button (expand ‘Advanced options’ in the
Command definition section if it is collapsed) and give it a suitable name, for
example INPUT_PATH. You can then put $INPUT_PATH in the command in
place of the fixed input file above, i.e.:
python example.py $INPUT_PATH
Tip
Parameters are passed to your job command at runtime as environment variables. We recommend using bash variable interpolation as in the above example to use your parameters as command line arguments, but you can also read them directly from the environment inside your command.
Parameters have some optional extra settings:
Type allows you to specify what format of inputs are permitted. The default (‘Text’) allows any input, while a ‘Number’ type parameter will only accept valid numbers.
Set a default value to determine a suitable default for a parameter when the job is run.
Toggle on ‘make mandatory’ to ensure that a parameter value is always provided to the job.
The below screenshot shows how the above example would look with a ‘Text’ type, no default set and ‘make mandatory’ enabled:

2. Server settings¶
In the server settings part of the job configuration, you can customise the server that your job will run on:

Use the job server type to determine what software you’d like preinstalled
on the server your job runs on. If you’re running a Python or R script, select
the matching server type, otherwise selecting Python is a sensible default.
When running a Python job, you also select the conda environment. Change from
the default Python3 to Python2 if you are running a script that does
not support Python 3.
You can optionally select one or more environments to be applied to your job server prior to running the job command. You can select any of the environments defined in the project. See the environments documentation for more information on creating environments.
In server resources select the amount of compute resources you need for your job. Either select a specific number of CPUs and amount of memory for a small or medium server on shared infrastructure or select a dedicated server. Dedicated servers can provide much more CPUs and memory than job instances, and some provide GPUs.
Note
Dedicated job servers need to be enabled to be visible in the configure job screen. If not present, contact your Faculty administrator to enable them.
3. Run settings¶
In the run settings section, you can configure additional settings for your job. Configure the maximum runtime to limit the maximum time that your job should take to run. If a run of the job exceeds this duration, it will be automatically stopped. This allows you to guard against stuck commands blocking useful resources and incurring extra computing costs.
Run a job¶
With your job configured, you can start a run using the ‘Run job’ button at the bottom of the screen. If your job has no parameters configured, you will be presented with a simple dialog where you confirm the command to be run and select if you start a single run or a run array (see Run arrays below). Click ‘Run’ to start the run and be taken to the run information screen.

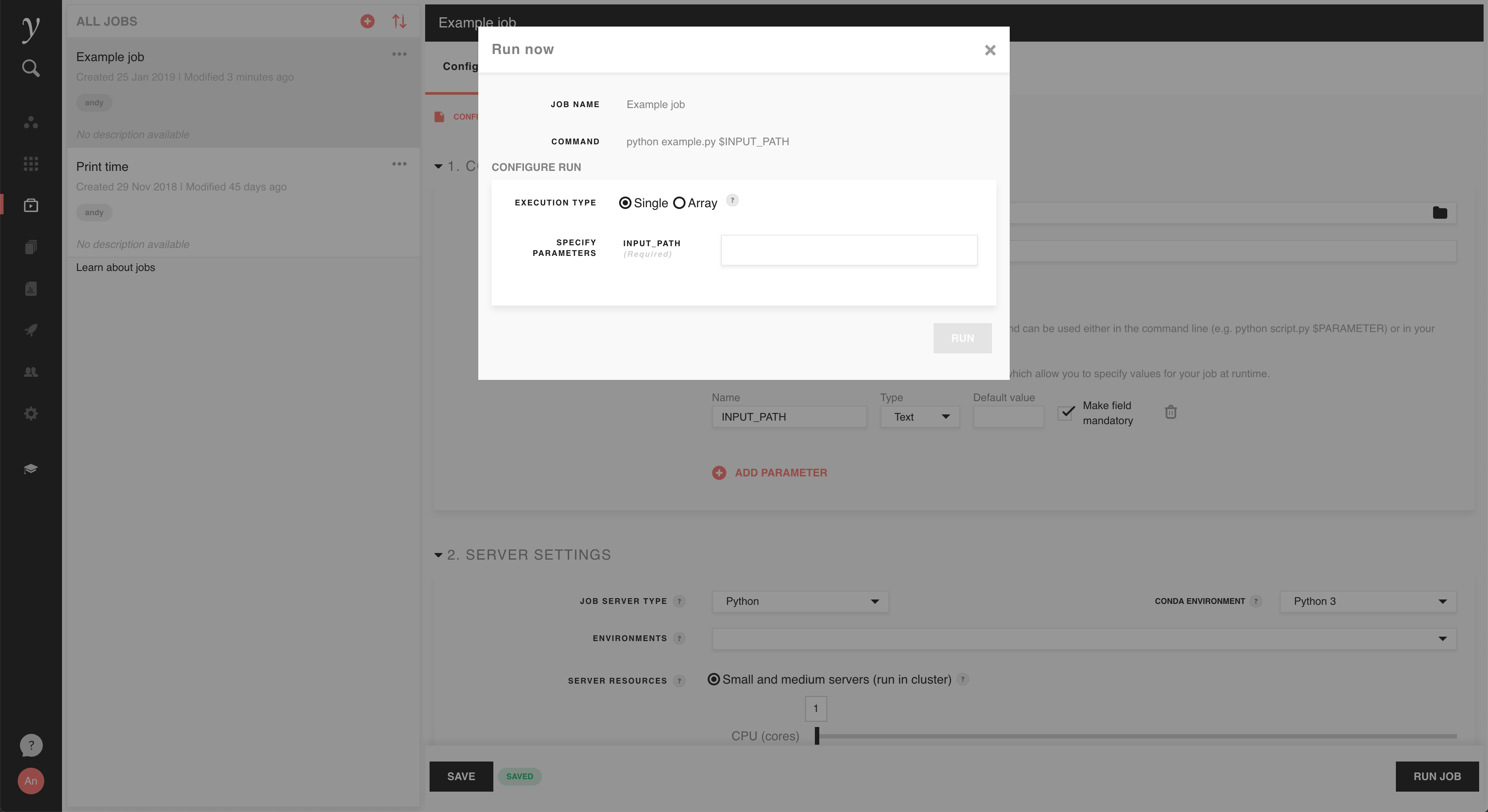
If you defined one or more parameters for your job, you’ll also be asked to enter values for those parameters for your run. In the example we gave in the Define a job section above, this would look like the screenshot below. Inputs will be validated according to the type and ‘make mandatory’ settings chosen in the job definition, and will be passed to the job command at runtime.
Run arrays¶
You can also choose to start a run array, in which you can run the same job many times at once and gather their outputs together. With ‘Array’ selected as the run’s execution type, choose 2 or more sub runs and input parameters for each of them (assuming that parameters have been configured for the job):
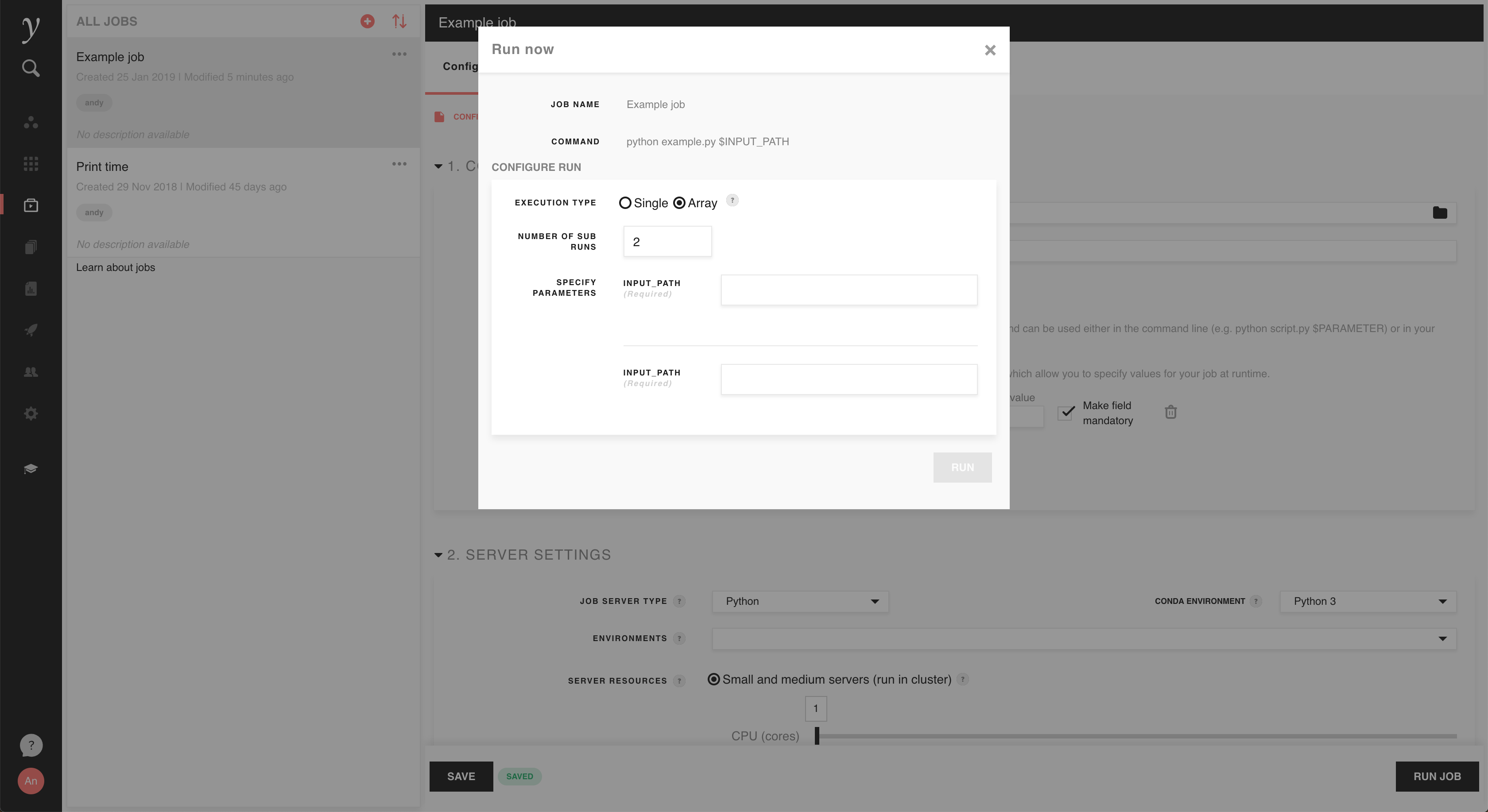
Instead of using the parameters feature, each sub run can also determine some
unit of work to perform using its sub run number, automatically passed to the
sub run as the environment variable FACULTY_SUBRUN_NUMBER.
View run status and outputs¶
On submission of a new run, you’ll be taken to the information screen for that run. It shows you detailed information about the run, such as the command and parameters used, run status, start and end times:
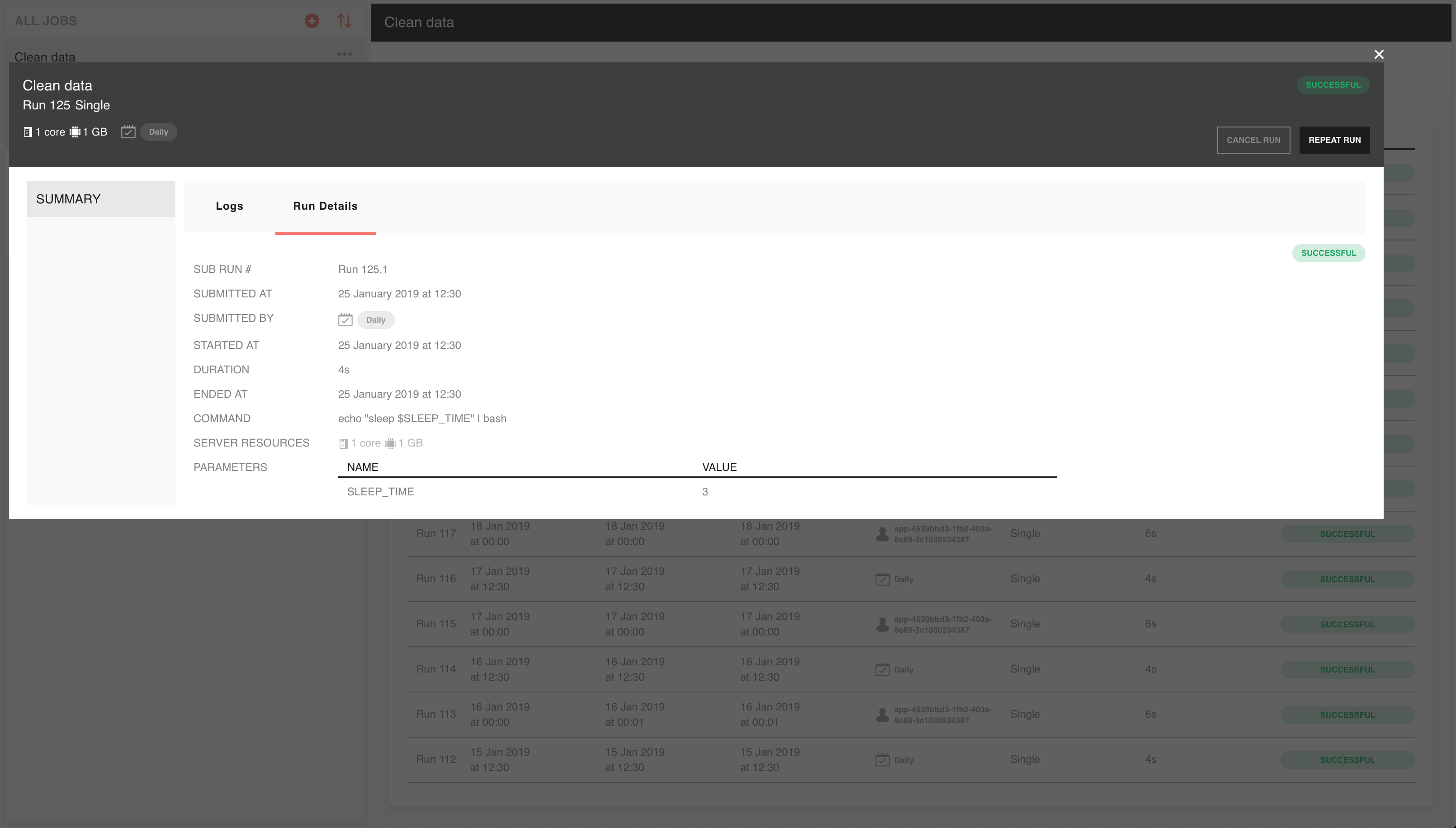
You can also choose to cancel a run or repeat the run from this screen, using the corresponding buttons at the top right.
You can also view any output generated by the job as it’s generated in the logs tab:
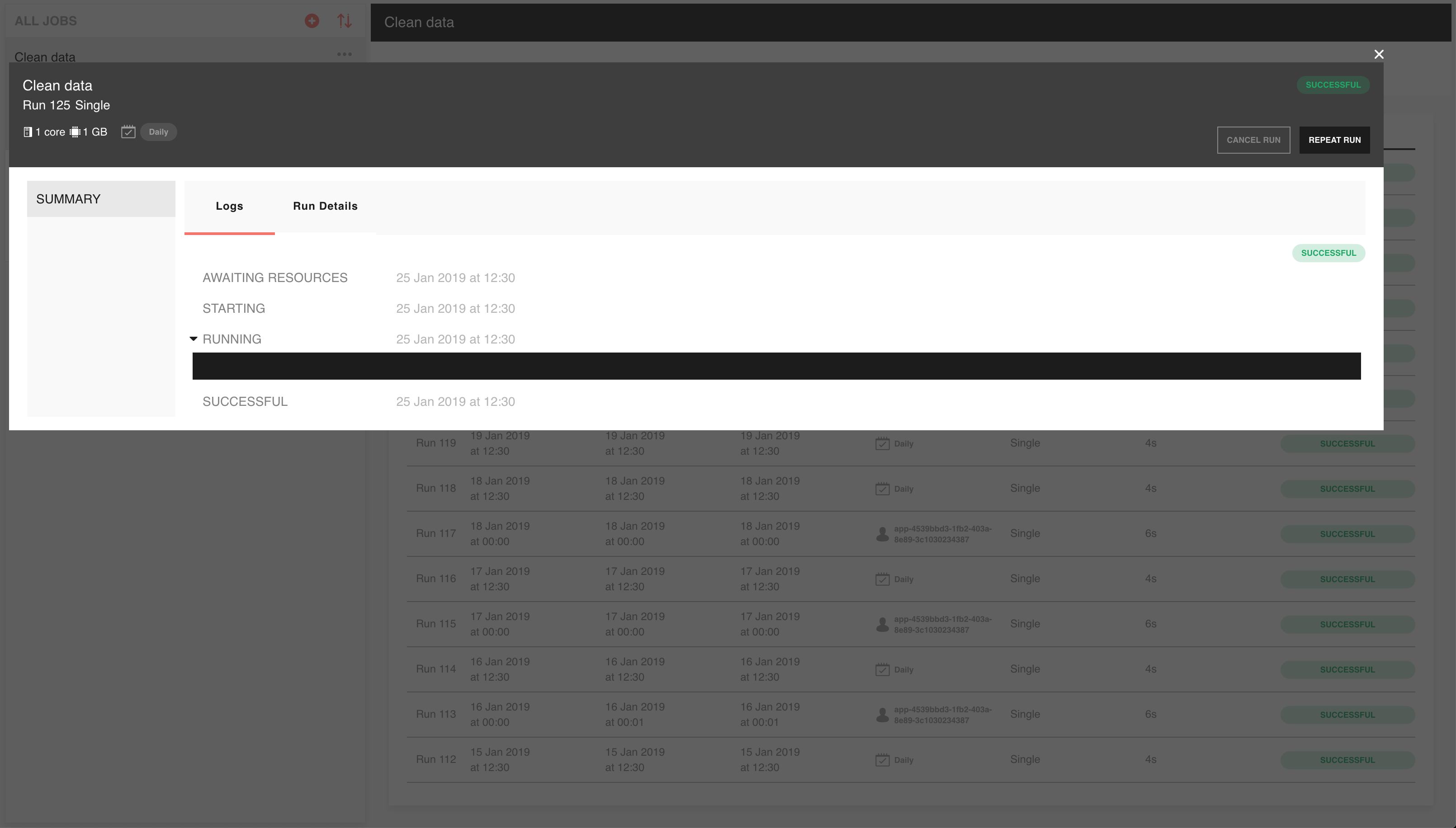
Come here to see the result of your job or to diagnose issues. Anything that’s printed out by your job while running or printed during application of any Faculty environments will be shown here.
When using run arrays, the run information screen will show a summary of all sun runs:

You can select any of the sub runs to see their information or log screens just as for single runs.
Job run history¶
You can come back and see information and logs about all previous runs for a job in the job history screen. You can find it in the history tab of running jobs:
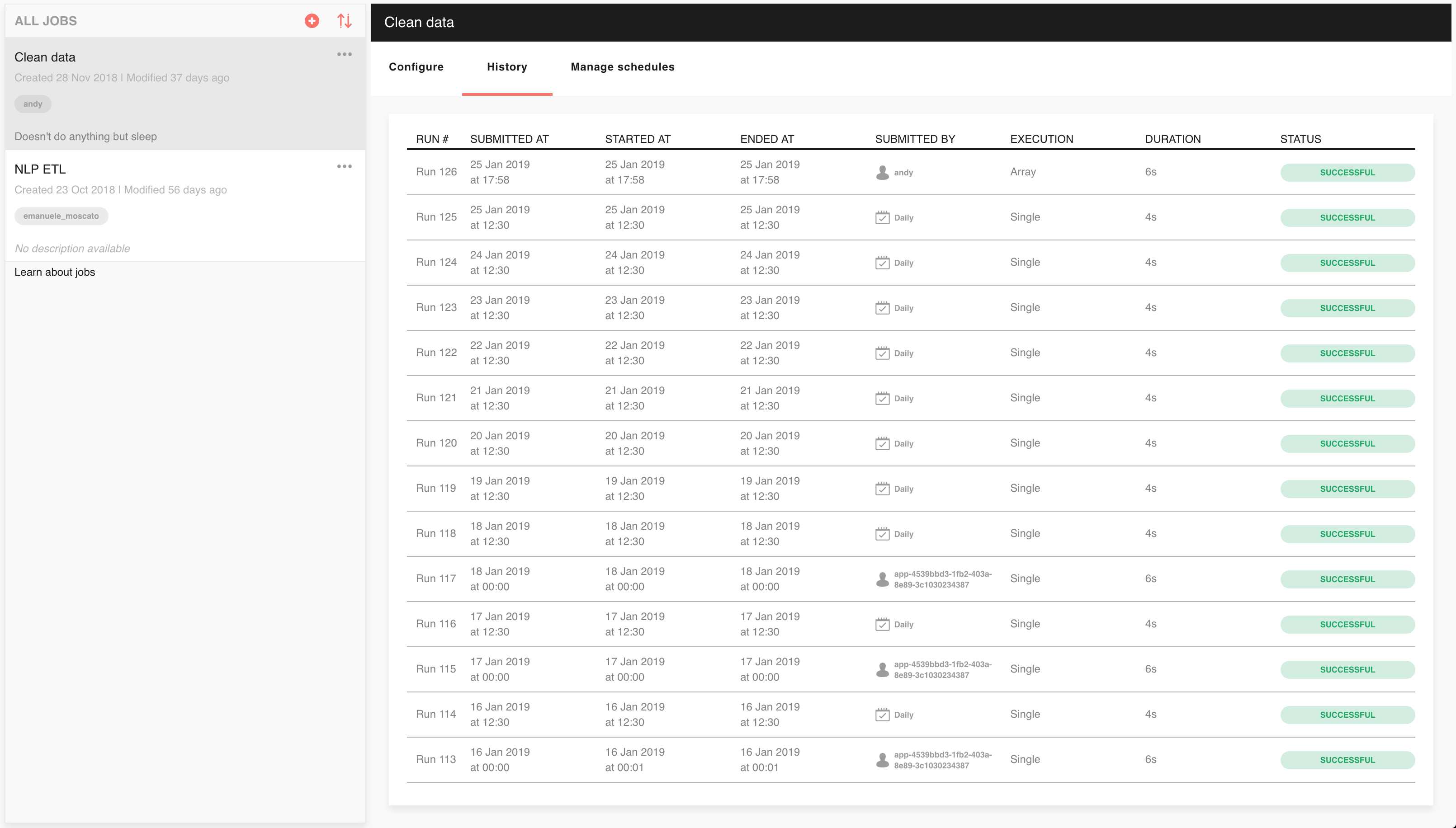
Here you’ll find a table summarising past runs of the job. Click on any of the displayed runs to view their information and logs screens.
Managing jobs using the command line client¶
As described above, jobs can be created in Faculty and run through the web
interface. In addition, faculty provides the ability to list and run jobs in a
project, and to view the logs for a run from the command line. You may find
this a more convenient way to manage jobs with large numbers of parameters
and/or large run arrays. Read
the faculty documentation for more information.