Models¶
Contents
In data science projects, at a certain point, a suitably trained model is identified, it is exported, and then used for making predictions in a production deployment. The provenance of the model (what training data and parameters went into a specific model), the choice of the model to be deployed in production, and the actual exported artifacts are often tracked in an ad-hoc way. This makes model management harder to do, especially if model training and deployment are handled by different teams.
Models on Faculty make model selection, tracking, versioning, and deployment a structured process. It connects Experiments with Apps and APIs, as well as external deployments, production infrastructure, and continuous integration pipelines.
Getting started¶
The Models view, that you can find in the sidebar, shows the registered models. This list starts off empty in a new project, and it is populated through the Experiments feature of Faculty.
The following sections describe how to add new models, manage them, and then use these models in Python.
Registering new models¶
New model from an experiment¶
The most straightforward way of registering a new model is by finding an experiment with exported model artifacts, selecting the export path of the artifact, and using the Register Model button:
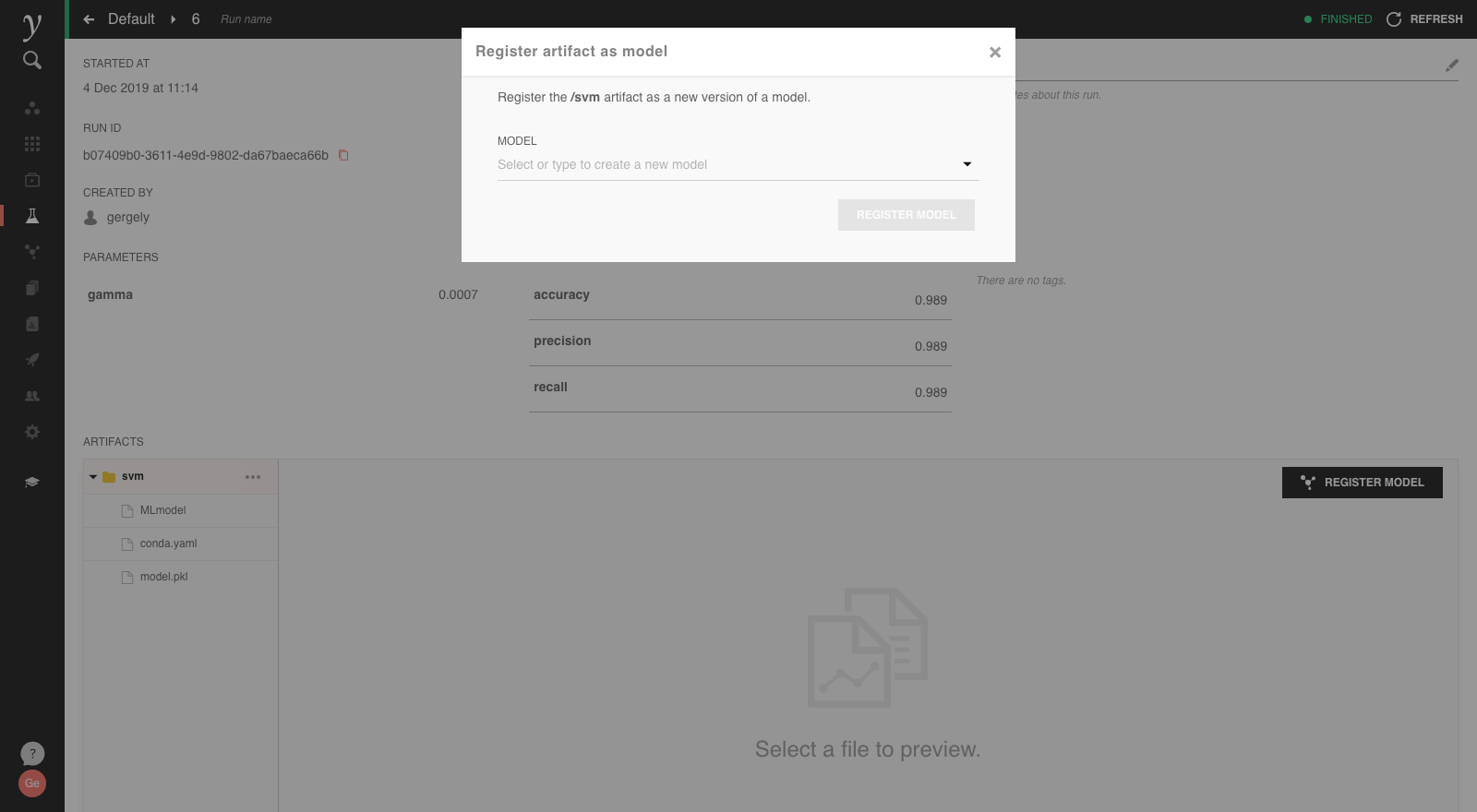
The prompt allows creating a new model by setting a new model name. Once the model is registered, it shows up in the Models view similar to this:

The list shows the model name and the latest version counter, here Version 1. This signifies that there are model artifacts associated with this registered model.
Clicking on the model’s listing in the view will bring up the model details:
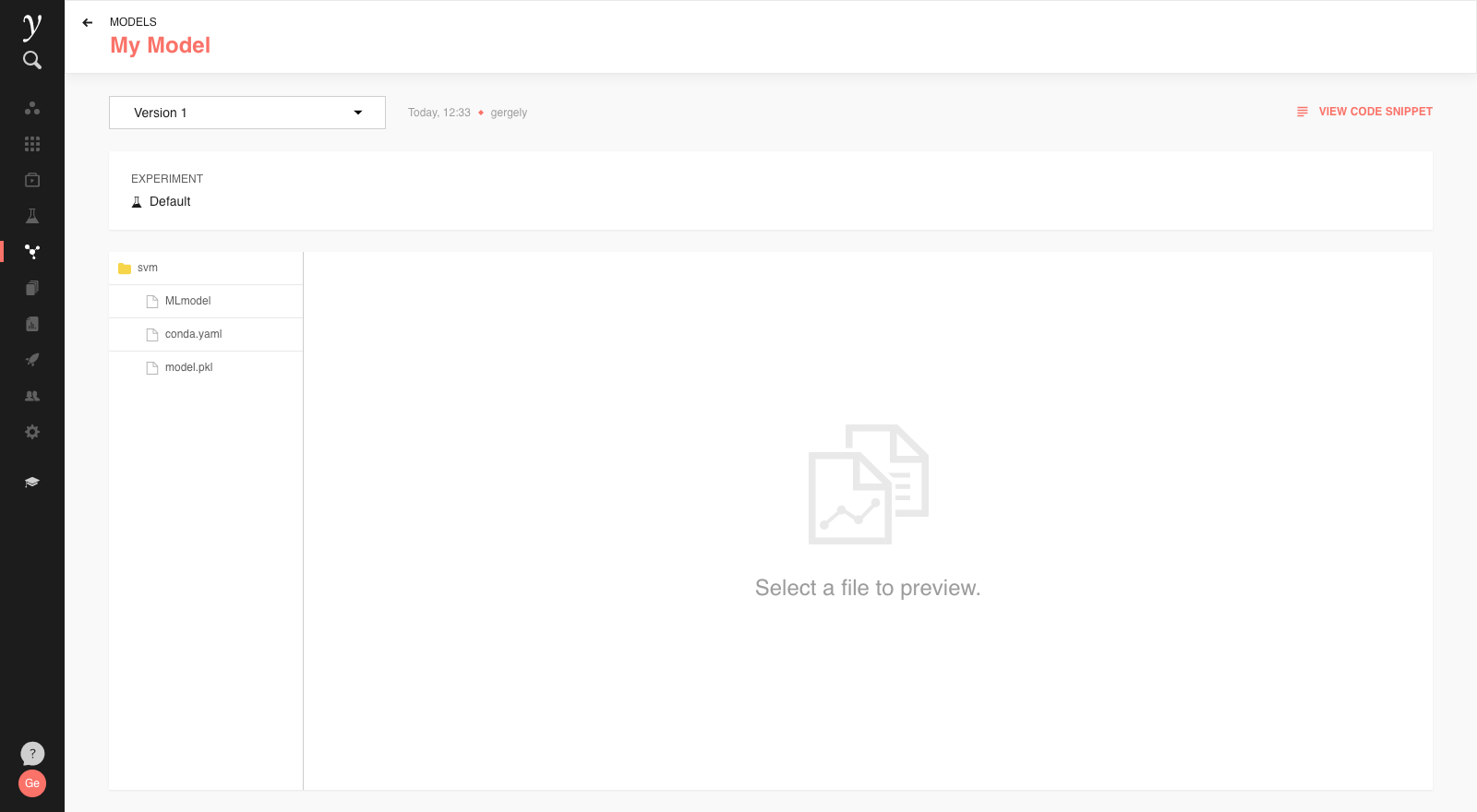
The details page also links back to the experiment that this model is originally from, allows inspecting the model artifacts, and provide other functionality discussed below (Versions and Code Snippets).
Creating an empty model¶
An alternate way of registering a new model is using the New Model button in the Models view, which creates an empty model (without any versions).
This popup also allows setting a model description directly at creation time. This can contain any notes that are helpful to know when consuming the model.
Clicking on this model will show that there are no contents yet:
To create the first model version from an experiment artifact, select this the relevant name from the dropdown when again using the Register Model tool. The dropdown will suggest the names of existing models.

This attaches the relevant artifacts to the existing model as Version 1.
Adding new model versions¶
Registered models can have multiple versions. Adding a new version is done by selecting an existing registered model in the pop-up of the Register Model tool. This is the same way how the initial version was added to a previously empty model (see above).
If a new model version is added, in the Models view the model will show “Version N”, where N is the latest version of the model.
On the model details page a dropdown allows to navigate between different versions and inspect the relevant artifacts:

Once registered, individual model versions cannot be removed.
Models view¶
In the Models view, models can be sorted by name or latest update. The model descriptions can be added or updated by using the context menu “⋯”, and the “Edit details” option:
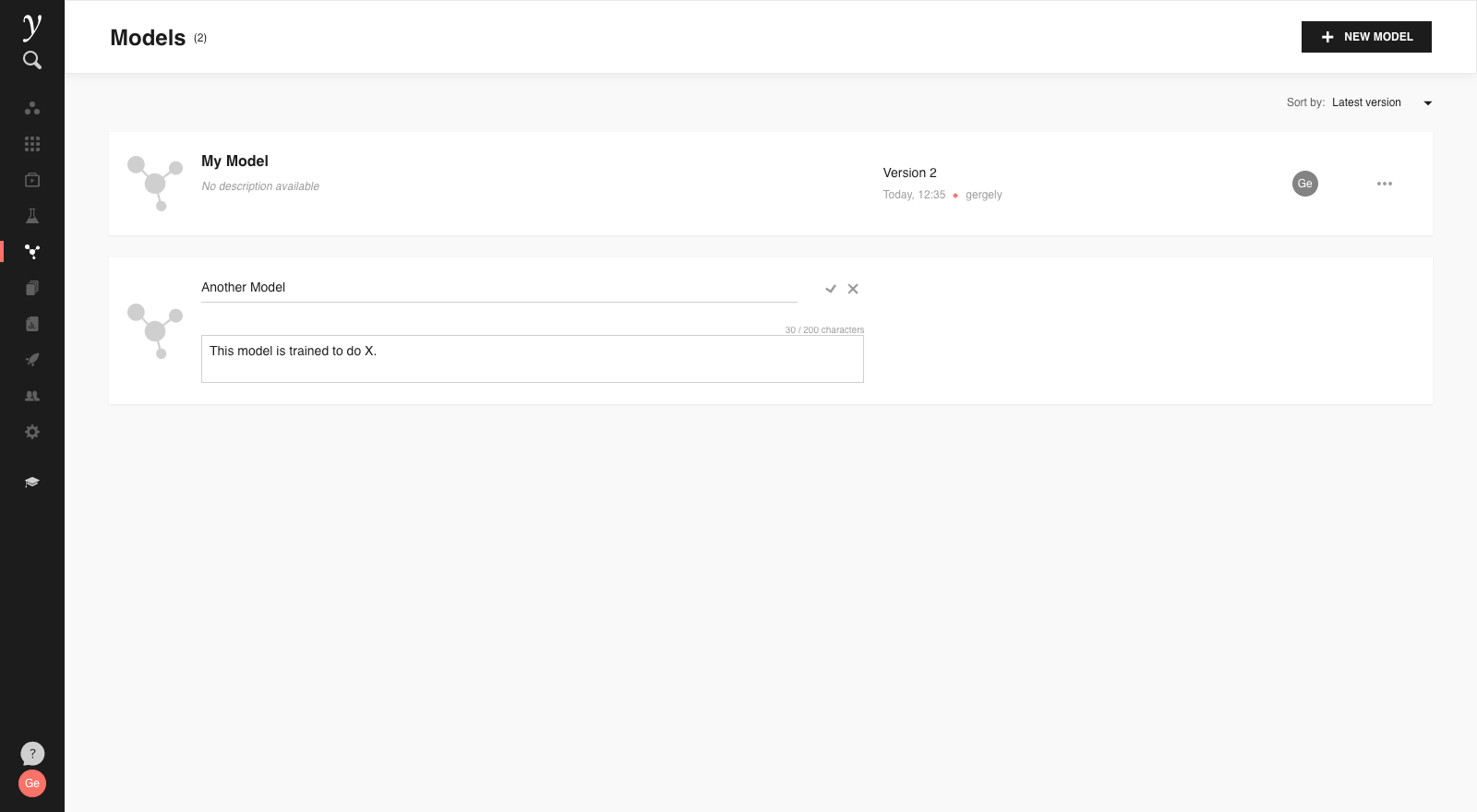
Registered models can also be deleted using the context menu.
Note
Once a model is deleted it cannot be recovered by the user.
Using registered models¶
Once a model is registered, the faculty_models Python library is
used to load it.
In each registered model’s details, the View Code Snippet menu provides the relevant code, which can be copied to a Python script or notebook, to easily load the specific registered model:
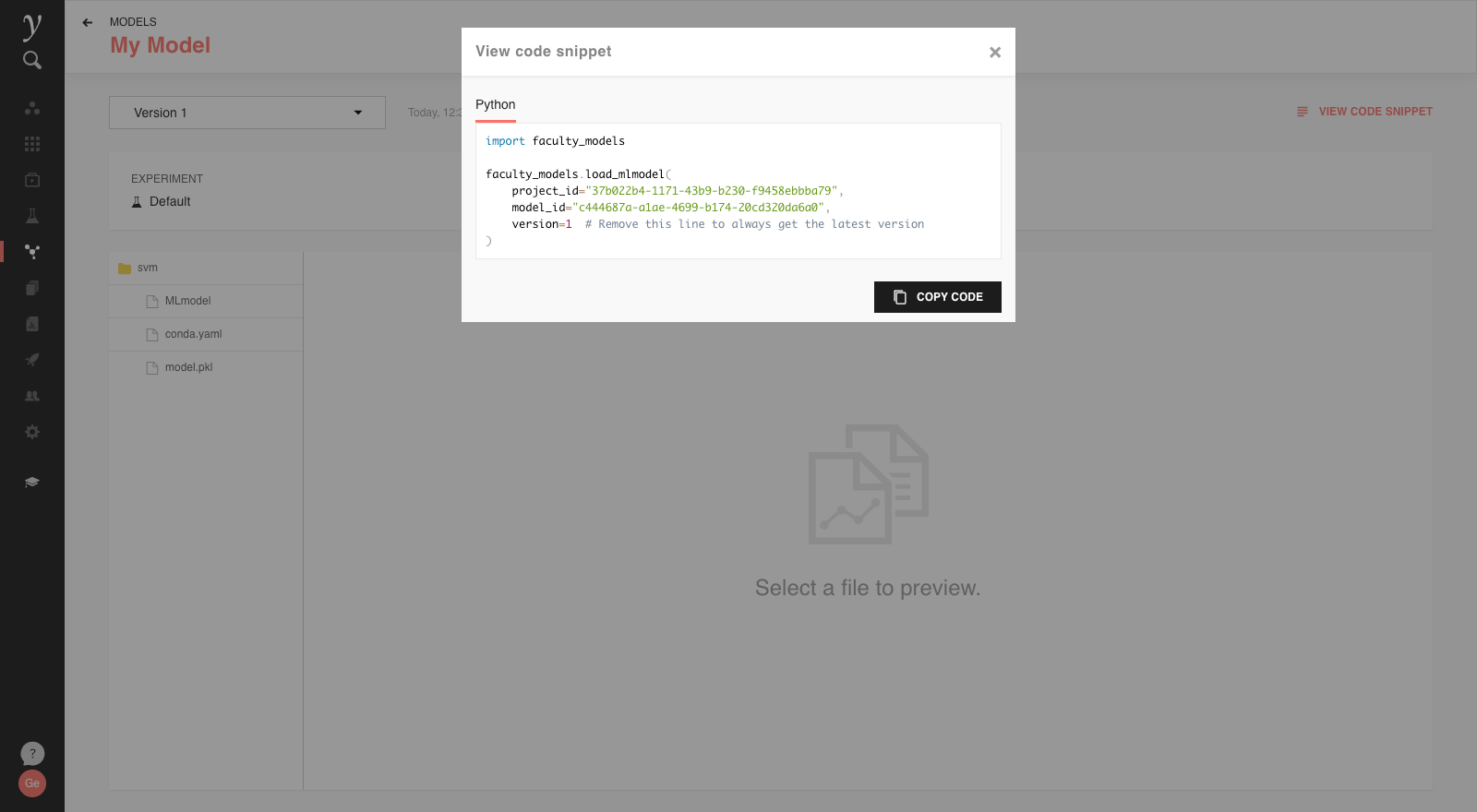
The code has the relevant project and model IDs prefilled, and a
version variable set.
Using version ensures that it’s always
known what version of the trained model is being used by the
given code. If that variable is removed from the code, the
latest version of the model is loaded on each call.
This control of the model version allows for workflows such as
QA/Testing before production release: when a new version of the
model is registered, the testing system can use that new version,
while the version value for the production system is only updated
once the testing is successful.
To use the registered model you are not required to run your code inside the Faculty infrastructure. In the case of external deployments or external production infrastructure, you’ll just need ensure that:
faculty_modelsis installed (e.g. withpip install faculty-modelsor listing it in yourrequirements.txtfile)you have created CLI credentials (see the relevant documentation) and make them available via environment variables or
.config/faculty/credentials.
After this the same code snippet works in external deployments as well.
For more information regarding the faculty_models library, check its
repository.